Appearance
浏览器渲染和解析 HTML 的过程
我们可以将这个过程分为 5 个阶段,分别是:
- 构建 DOM
- 将 HTML 解析成一个个的 Tokens
- 将 Tokens 解析成 Object(ast)
- 将 object 组合成 DOM Node 树
- 构建 CSSOM
- 解析 CSS 文件,并构建 CSSOM 树的过程
- 构建 Render Tree
- 配合 DOM 树和 CSSOM 树通过从右向左匹配构建出一个 Render 树
- Layout
- 计算出每一个元素对于 viewport 的相对位置
- Paint
- 将 Render 树转换成像素,绘制到屏幕上
构建 DOM
DOM(文档对象模型),当浏览器发出请求并接收到 content-type 为'text/html'类型的数据时,就网络进程就与渲染进程建立了通道,然后加载了多少就处理多少,将加载的字节流信息通过一下步骤转换成 DOM 类型的树结构。具体流程可以分为: 字节流 bytes => 分词器解析 Tokens => 生成一个个 Node 节点对象 => 将 Node 节点组装成树结构
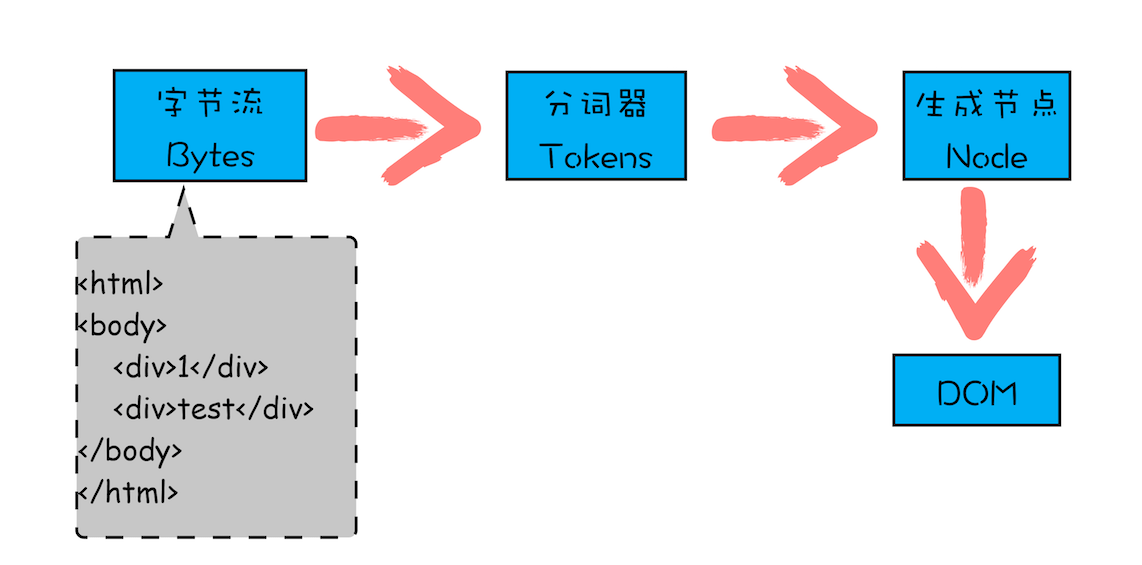
字节流到 Tokens
解析 HTML 就是通过分词器先将字节流转换为一个个 Token,分为 Tag Token 和文本 Token。具体的流程可以参考 Vue 中编译流程的 Parse 的过程
其主要信息包含如下:
- m_name : tagName 标签的名称 (html、div、xxx)
- m_type : 标签的类型 (html、div、xxx)
ts
enum TokenType {
Uninitialized,
DOCTYPE, // 文档节点
StartTag, // 标签开始节点类型
EndTag, // 标签闭合节点类型
Comment, // 注释节点类型
Character, // 文本节点类型
EndOfFile,
}- attr: 标签的属性,缓存了标签节点上的属性信息,如: class="u-text"
- text: 文本 Token 才有的属性

Token 到 AST 对象 和 组装成树结构
需要注意的是:从 token 到 AST 对象;在将 AST 对象构建成 DOM 树的过程不是分步进行的,而是同时进行的。
从构建 DOM 节点树的过程你会发现跟 Vue 的编译流程很像,也是根据 token 分词的类型不同去调用不同的创建函数,然后不断的向后推进的过程。其中对于不同的标签节点也通过继承的方式去合并了很多属性或者方法,如
- 维护整个标签树位置的属性: m_previous m_next 、m_parentOrShadowHostNode 、 m_firstChild 、m_lastChild
- 维护节点文档信息的公共属性: m_document(维护了
[dom].ownerDocument属性)
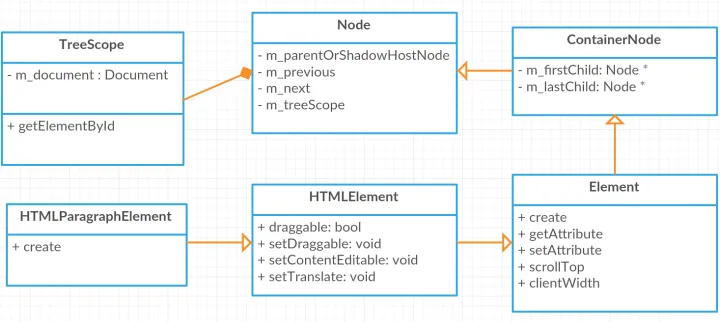
渲染进程维护了一个 Token 的栈,通过这个 Token 栈去维护 DOM 的树结构。当遇到一个开始标签的(StartTag)的时候就将其 Push 到栈中,然后遇到一个结束标签(EndTag)的时候就从栈里面拿出一个开始标签。这样就生成了一个 DOM 树的结构
构建 CSSOM
CSSOM(CSS Object Model,CSS 对象模型),在 HTML 中我们对于样式可以通过多种方式进行定义:
- 内联样式
html
<html>
<head>
<style>
p {
}
</style>
</head>
<body></body>
</html>对于内联样式,其执行并构建 CSSOM 的流程是包含在 ParseHTML 的过程中
- link 外部样式
html
<html>
<head>
<link href="./theme.css"/>
</style>
</head>
<body></body>
</html>对于外部样式,当解析到这个标签的时候,渲染引擎会新开一个网络请求去加载此 CSS 文件,并继续向下解析 HTML。当 CSS 文件加载完成(onload)后,跟构建 DOM 的流程很相似,然后通过词法分析的方式去解析整个 CSS 文件,并将内容转换成一个 CSSStyleSheet 对象。

其具体流程可以分为以下几个步骤:
- 加载 CSS
这里面就涉及到一个问题: 为什么建议 CSS 文件放在 head 中且不建议很大?
CSS 文件和 JS 文件一个很大的区别就是: 当 HTML 中解析到 CSS 文件和 JS 文件,且 HTML 已经解析完成。那么这时候
- 如果 JS 文件没有加载完成 那么浏览器还是按照固定的流程去生成 Render Tree,页面会有结果出现
- 如果 CSS 文件没有加载完成, 那么浏览器不会进入 Render Tree 的流程,会阻碍页面的渲染,页面会出现白屏问题
- 解析 CSS
解析 CSS 的流程跟 DOM 流程很像,也是 字节码 => 词法分析格式化成 Tokens => StyleRule => 四类哈希 Map(id、class、tag、shadowPseudoElementRules)
2.1. 字节码 => 词法分析格式化成 Tokens
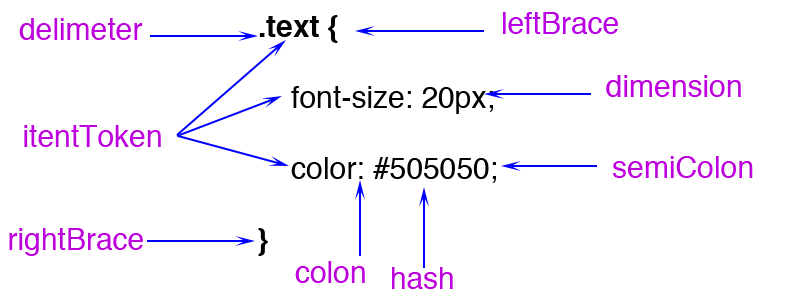
这边涉及到一个问题: 为什么颜色建议使用 16 位数值,而不是 rgb?
因为对于 RGB 类型的颜色其转换成的 Token 是函数类型的(FunctionToken),那么在计算的时候就每次就需要计算得到结果,而不是直接使用
2.2. 词法分析格式化成 Tokens => StyleRule
对于 StyleRule 我们主要关注两个部分: 1. Style 的选择器规则。 2. Style 的属性集。下面分别简单了解一下这两个部分
- Style 的选择器规则
css
.u-text p {
font-size: 14px;
margin: 10px;
}对于上述 CSS 其规则有两个 .u-text 和 p。 那么对于这个样式其会按照 从右向左 的顺序生成样式的匹配规则。即
js
[{
value = "u-text" , matchType = "Class" , relation = "Descendant"
},{
value = "p" , matchType = "Tag" , relation = "SubSelector"
}]原因:因为 HTML 的解析不是等 html 内容下载完成才进行的,所以当你执行 CSS 的选择器的时候,可能这个元素还没有解析并添加到 DOM 树中,那么这时候从左到右的时候,只有到最后的选择器才知道元素不存在。如果从右到左那么就可以第一次判断的时候大概率知道元素是否存在了。
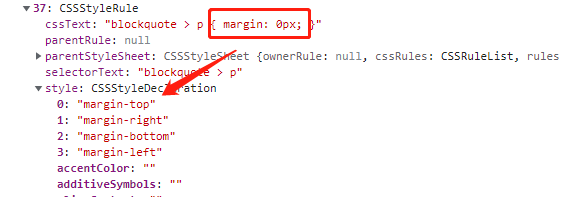
- Style 属性集
对于上面的 margin:10px;的属性,其虽然是一个合并的属性(margin-top|right|vbottom|left),但是解析成属性集的时候仍然会拆分为单个的
2.3. StyleRule => 四类哈希 Map(id、class、tag、shadowPseudoElementRules)
这一步的作用是什么?主要是为了 CSS 的权重做准备的。从 CSS 的计算权重知道对于一个 CSS 属性,其权重大小分别为: important > style > id > class > tag > 伪类。那么这时候就可以将 CSS 文件中的样式按照 id > class > tag > 伪类 的分类进行分类处理。
RenderTree 过程
前面两个过程分别构建出了 DOM 树 和 CSSOM 对象,但是 DOM 树和 CSSOM 还没有匹配,且还有一个特殊的属性 dispaly:none使得节点不需要渲染也没有特殊处理,那么这个流程就是进行这个的流程
- 按照 DOM 树和 CSSOM 树构建出最终的包含 CSS 样式的 DOM 树
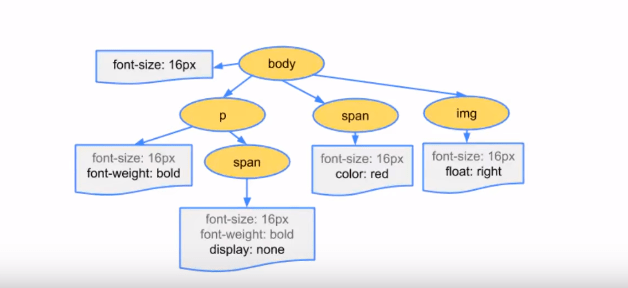
这个流程是一个按照 DOM 树进行深度优先的遍历过程,这个过程分为两个步骤:
- 按照 id、class、伪元素、标签、通配符顺序去前面 HashMap 中匹配获取到当前节点匹配中的样式
- 按照 父类继承的样式 -> UA 默认的样式 -> 匹配中的样式 来设置元素的真正样式
- 过滤真正需要渲染的元素
在 DOM 树中包含了很多不需要渲染的元素节点: head、display:none的节点、...; 那么这个过程也是获取到这些真正渲染的 Render 树
Layout 的过程
上一步获取到真正需要渲染的节点树,同事也获取到每一个节点最终的 style 属性,这时候就按照元素的盒模型计算出每一个元素相当于 Viewport 的位置和大小()
Paint
这一步就是交给 CPU 按照像素去渲染整个图片了
JS 的影响
在 html 中加入 JS 主要分为下面几种方式
- 内联 JS 脚本
- 通过 script 去引入外部脚本文件
那么这两个分别对 HTML 的解析、CSS 文件的解析造成哪些影响?
结论: 除非设置了 defer 和 async,不然 JS 的下载和执行会阻塞 DOM 的解析工作,同时 JS 执行过程可能会涉及到获取元素的样式,所以 JS 的执行前需要确保 CSSOM 已经构建完成。
例外:async 和 defer 虽然都是异步的,不过还有一些差异,使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行。
html
<html>
<head>
<link href="style.css" rel="stylesheet" />
<script type="text/javascript" src="foo.js"></script>
<script type="text/javascript" src="defer.js" defer></script>
<script type="text/javascript" src="async.js" async></script>
</head>
<body>
<script>
let div1 = document.getElementsByTagName("div")[0]
div1.innerText = "time.geekbang"
</script>
<div>1</div>
<div>test</div>
</body>
</html>分析:
js
// 1. 解析到link,触发style.css的下载 // 下载完成后立即执行
// 2. 解析到script,触发 foo.js的下载 // 默认是 async ,下载完成后立即执行
// 3. 解析到script,触发 defer.js的下载 // DOMContentLoaded事件之前执行
// 4. 解析到script,触发 async.js的下载 // 下载完成后立即执行
// 5. 假如前面的都没有下载完成,会继续进行DOM的解析,这时候触发script 立即解析并执行
// 这时候会触发一个判断条件 style.css执行好了么(CSSOM构建完成了么)。 如果没有构建完成那么就会挂起等待CSSOM构建完成
// 6. 继续向下解析DOM。 如果这时候发现 foo.js加载完成,那么又会挂起DOM的解析CSS 的影响
** JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行**
重点
CSSOM 的作用是什么?
CSS 与 JS 对 DOM 的影响
- CSS 不阻塞 dom 的生成。CSS 不阻塞 js 的加载,但是会阻塞 js 的执行。
- js 会阻塞 dom 的生成,也就是会阻塞页面的渲染,那么 css 也有可能会阻塞页面的渲染。