Appearance
Yarn
相对于 npm 之前的很多问题,yarn 进行了改进,优化点如下
- 确定性(yarn.lock) 通过 yarn.lock 等机制,保证了确定性。即不管安装顺序如何,相同的依赖关系在任何机器和环境下,都可以以相同的方式被安装。(在 npm v5 之前,没有 package-lock.json 机制,只有默认并不会使用的 npm-shrinkwrap.json。)
- 采用模块扁平安装模式 将依赖包的不同版本,按照一定策略,归结为单个版本,以避免创建多个副本造成冗余(npm 目前也有相同的优化)。
- 网络性能更好 Yarn 采用了请求排队的理念,类似并发连接池,能够更好地利用网络资源;同时引入了更好的安装失败时的重试机制。
- 采用缓存机制,可以实现离线模式
其缓存存放在公共目录(yarn cache dir).
优先使用网络数据,如果网络数据不存在才会使用缓存数据
注意
其实对于这些问题,在 npm v5 之后也都一一引入了
Yarn 的安装机制
检测(checking)→ 解析包(Resolving Packages) → 获取包(Fetching Packages)→ 链接包(Linking Packages)→ 构建包(Building Packages)
检测包(checking)
这一步主要是检测项目中是否存在一些 npm 相关文件,比如 package-lock.json 等。如果有,会提示用户注意:这些文件的存在可能会导致冲突。在这一步骤中,也会检查系统 OS、CPU 等信息。
解析包(Resolving Packages)
这一步会解析依赖树中每一个包的版本信息。
首先获取当前项目中 package.json 定义的 dependencies、devDependencies、optionalDependencies 的内容,这属于首层依赖。
接着采用遍历首层依赖的方式获取依赖包的版本信息,以及递归查找每个依赖下嵌套依赖的版本信息,并将解析过和正在解析的包用一个 Set 数据结构来存储,这样就能保证同一个版本范围内的包不会被重复解析。
对于没有解析过的包 A,首次尝试从 yarn.lock 中获取到版本信息,并标记为已解析;
如果在 yarn.lock 中没有找到包 A,则向 Registry 发起请求获取满足版本范围的已知最高版本的包信息,获取后将当前包标记为已解析。
总之,在经过解析包这一步之后,我们就确定了所有依赖的具体版本信息以及下载地址。
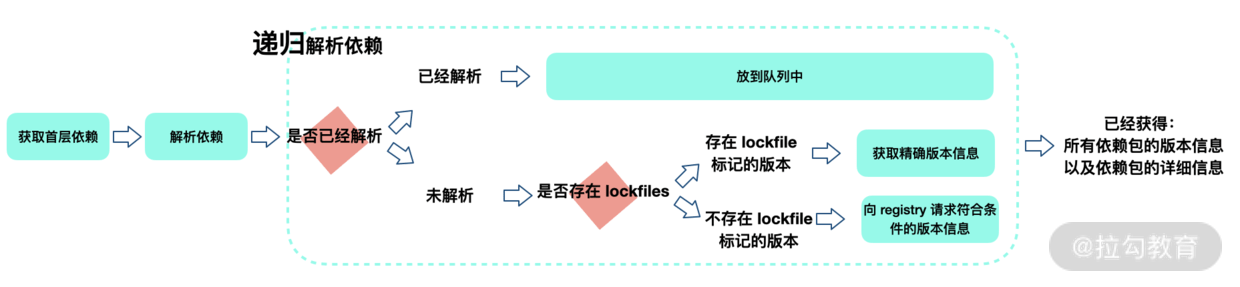
解析包获取流程图
获取包(Fetching Packages)
这一步我们首先需要检查缓存中是否存在当前的依赖包,同时将缓存中不存在的依赖包下载到缓存目录。说起来简单,但是还是有些问题值得思考。
比如:如何判断缓存中是否存在当前的依赖包?其实 Yarn 会根据 cacheFolder+slug+node_modules+pkg.name 生成一个 path,判断系统中是否存在该 path,如果存在证明已经有缓存,不用重新下载。这个 path 也就是依赖包缓存的具体路径。
对于没有命中缓存的包,Yarn 会维护一个 fetch 队列,按照规则进行网络请求。如果下载包地址是一个 file 协议,或者是相对路径,就说明其指向一个本地目录,此时调用 Fetch From Local 从离线缓存中获取包;否则调用 Fetch From External 获取包。最终获取结果使用 fs.createWriteStream 写入到缓存目录下。
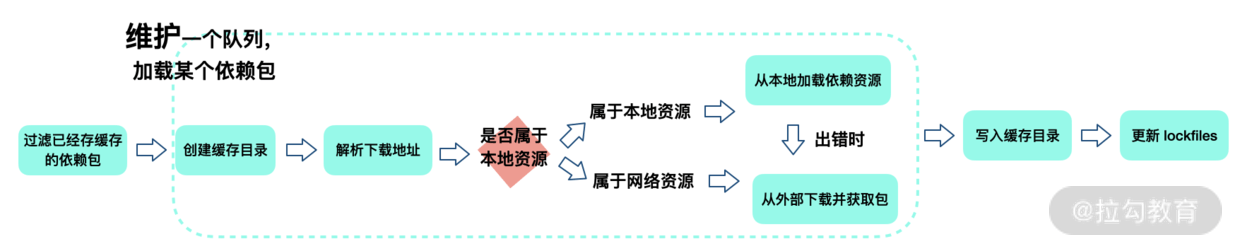
获取包流程图
链接包(Linking Packages)
上一步是将依赖下载到缓存目录,这一步是将项目中的依赖复制到项目 node_modules 下,同时遵循扁平化原则。在复制依赖前,Yarn 会先解析 peerDependencies,如果找不到符合 peerDependencies 的包,则进行 warning 提示,并最终拷贝依赖到项目中。
这里提到的扁平化原则是核心原则,我也会在后面内容进行详细的讲解。
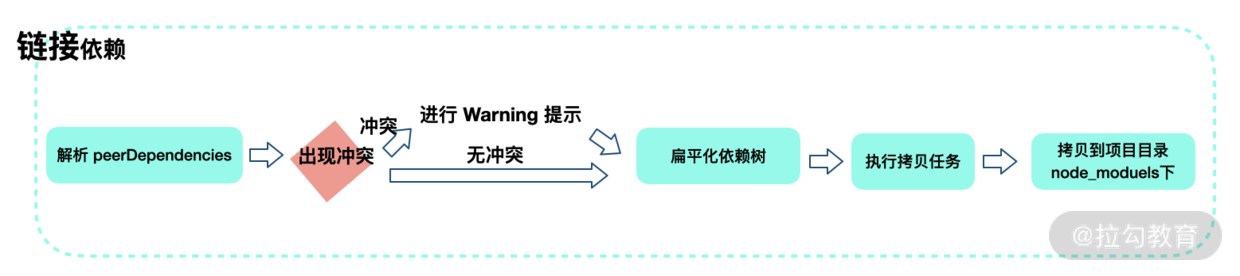
链接包解析流程图
构建包(Building Packages)
如果依赖包中存在二进制包需要进行编译,会在这一步进行。
了解了 npm 和 Yarn 的安装原理还不是“终点”,因为一个应用项目的依赖错综复杂。接下来我将从“依赖地狱”说起,帮助你加深对依赖机制相关内容的理解,以便在开发生产中灵活运用。