Appearance
chunk 图的生成
- chunkGroup
由 chunk 组成,一个 chunkGroup 可以包含多个 chunk,在生成/优化 chunk graph 时会用到;
- chunk
由 module 组成,一个 chunk 可以包含多个 module,它是 webpack 编译打包后输出的最终文件;
- module
就是不同的资源文件,包含了你的代码中提供的例如:js/css/图片 等文件,在编译环节,webpack 会根据不同 module 之间的依赖关系去组合生成 chunk
对于我们例子中的 main.js,他是一个入口 module 所以会在 addEntry 的时候添加到_preparedEntrypoints 中去,那么在 seal 中的处理
js
class Compilation extends Tapable {
/**
* @param {Callback} callback signals when the seal method is finishes
* @returns {void}
*/
seal(callback) {
this.hooks.seal.call();
while (
this.hooks.optimizeDependenciesBasic.call(this.modules) ||
this.hooks.optimizeDependencies.call(this.modules) ||
this.hooks.optimizeDependenciesAdvanced.call(this.modules)
) {
/* empty */
}
this.hooks.afterOptimizeDependencies.call(this.modules);
this.hooks.beforeChunks.call();
/*
在我们处理入口文件(addEntry)和异步module(_addModuleChain)的时候都会讲一个slot保存到this._preparedEntrypoints中
如我们的 main.js
*/
for (const preparedEntrypoint of this._preparedEntrypoints) {
// 获取准备作为一个入口module的module
const module = preparedEntrypoint.module;
// 名称
const name = preparedEntrypoint.name;
// 根据入口module的名称生成一个 chunk ,并且保存在 this.namedChunks()中去
const chunk = this.addChunk(name);
// 生成一个 enterpoint实例对象 enterpoint 继承与 ChunkGroup 所以其实际上也是根据name创建一个chunkGroup对象
const entrypoint = new Entrypoint(name);
entrypoint.setRuntimeChunk(chunk);
entrypoint.addOrigin(null, name, preparedEntrypoint.request);
this.namedChunkGroups.set(name, entrypoint);
this.entrypoints.set(name, entrypoint);
this.chunkGroups.push(entrypoint);
// 建立 chunk 与 chunkGroup的关系
GraphHelpers.connectChunkGroupAndChunk(entrypoint, chunk);
// 建立 chunk 与 module 的关系
GraphHelpers.connectChunkAndModule(chunk, module);
// 保存当前chunk 的入口 module
chunk.entryModule = module;
chunk.name = name;
this.assignDepth(module);
}
// 处理chunkGroup
buildChunkGraph(
this,
/** @type {Entrypoint[]} */ (this.chunkGroups.slice())
);
this.sortModules(this.modules);
this.hooks.afterChunks.call(this.chunks);
this.hooks.optimize.call();
}
}从上面我们可以看出对于入口 Module 其通过const chunk = this.addChunk(name);创建了一个入口 chunk,这时候 chunk 还是个空的对象,然后又根据 name 创建了一个入口的 entrypoint(其实也就是一个 chunkGroup),这时候 chunkGroup 也是一个空的对象。
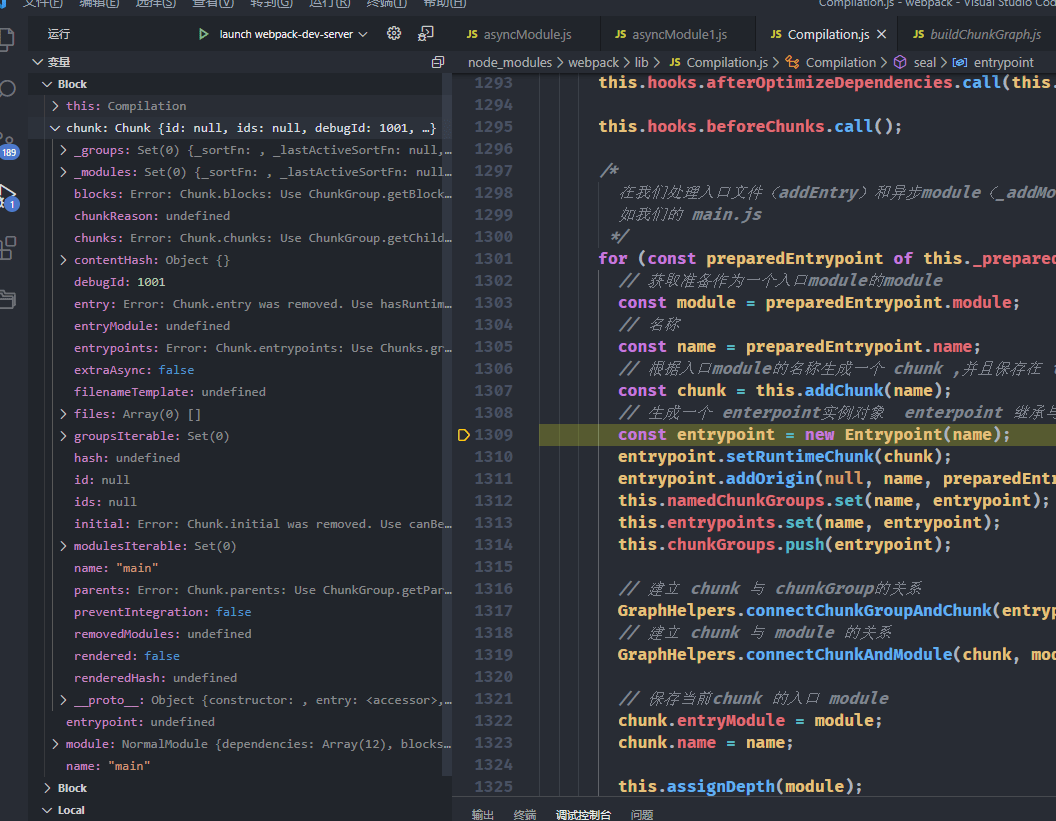
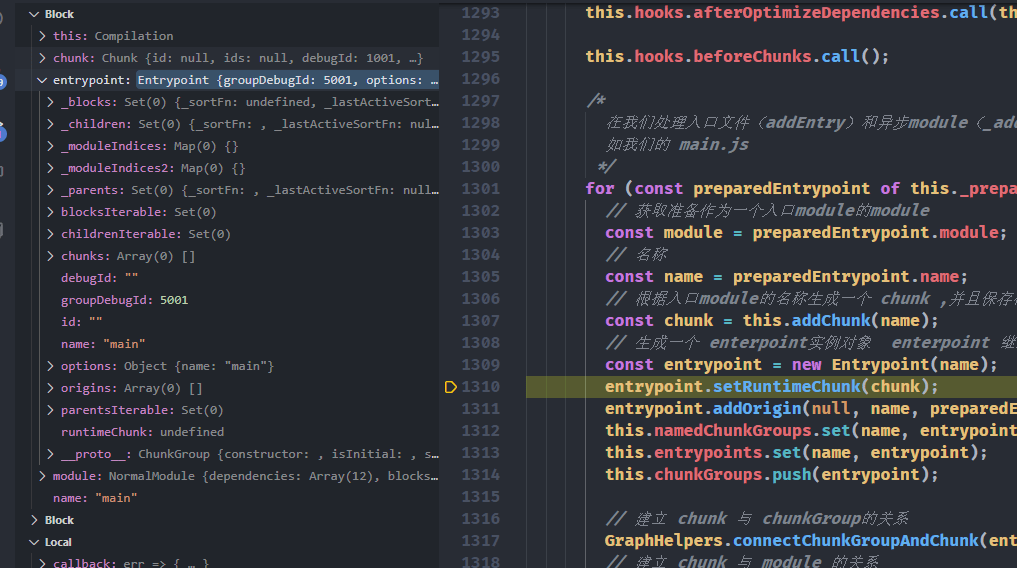
然后通过GraphHelpers.connectChunkGroupAndChunk(entrypoint, chunk);和GraphHelpers.connectChunkAndModule(chunk, module);分别建立的 entrypoint 和 chunk、chunk 和 module 之间的关系

下面是buildChunkGraph(this, (this.chunkGroups.slice()));,这一步主要是通过双层遍历的方式去建立当前 chunk 的_modules 与子同步 module 之间的关系,
如我们例子中的 main.js
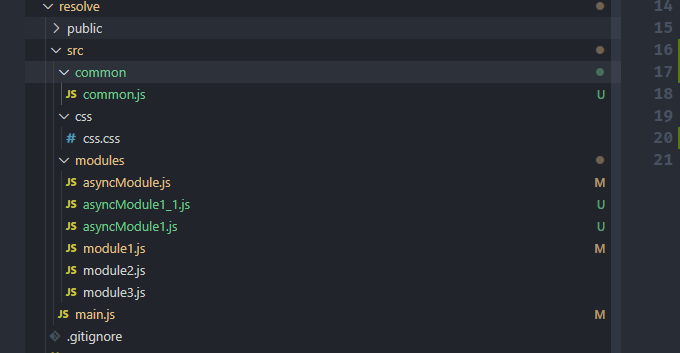
其存在 9 个 module,存在四个异步的 module(asyncModule.js,asyncModule1_1.js,asyncModule1.js,css.css)。其入口 module 为 main.js,那么一开始的时候上面只有:
一个 chunk:
js
mainChunk = {
_modules: [mainModule],
_groups: [mainChunkGroup],
};一个 chunkGroup:
js
mainChunkGroup = {
chunks: [mainChunk],
};buildChunkGraph()
这分为两个步骤:
第一步: visitModules
我们先看一下在 complaition.modules 中 module 的数据,发现在 make 的过程中其就通过 parse 将一个入口中所有的 module 都存在放在complaition.modules中。
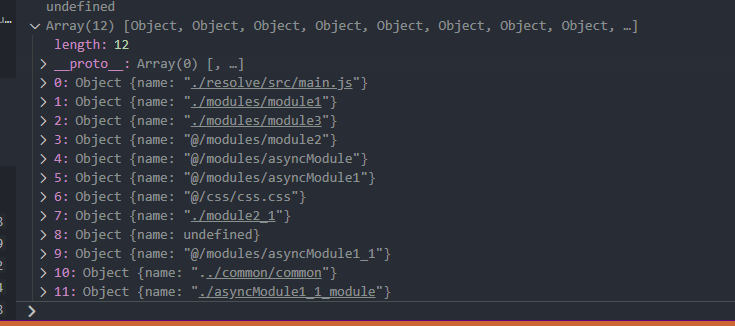
那么通过 const blockInfoMap = extraceBlockInfoMap(compilation);主要是将上面的 module 依赖的同步或者异步进行分类,即在 complaition.modules 中每一个 module 都会对应的变成 { key : module对象 , value : { modules : [当前module中依赖的子同步module] , blocks:[当前module中依赖的子异步module] }},特别注意是子 module,不包含子 module 再依赖的 module。最后其转换后的结果为 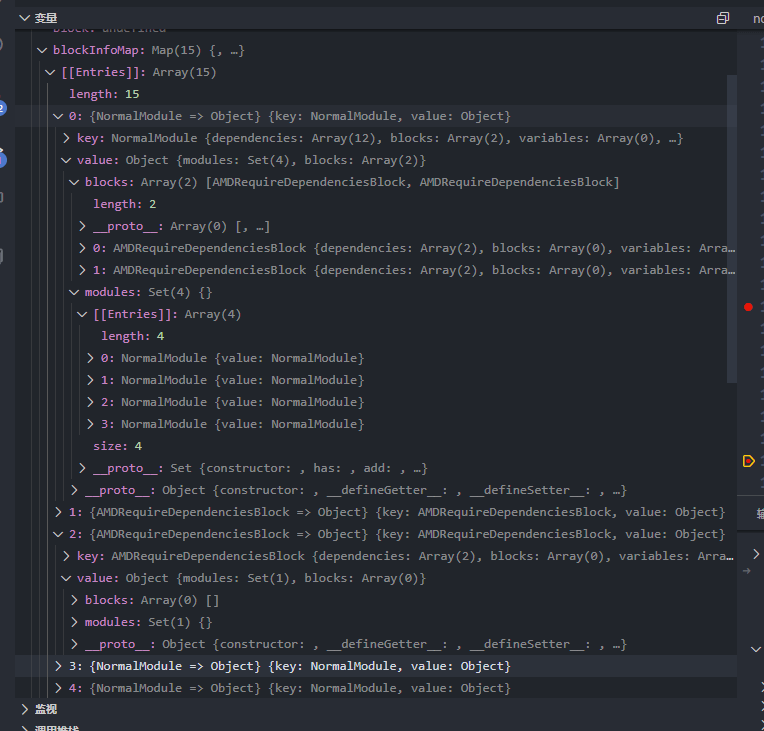
也就是变成了这样下图那样:
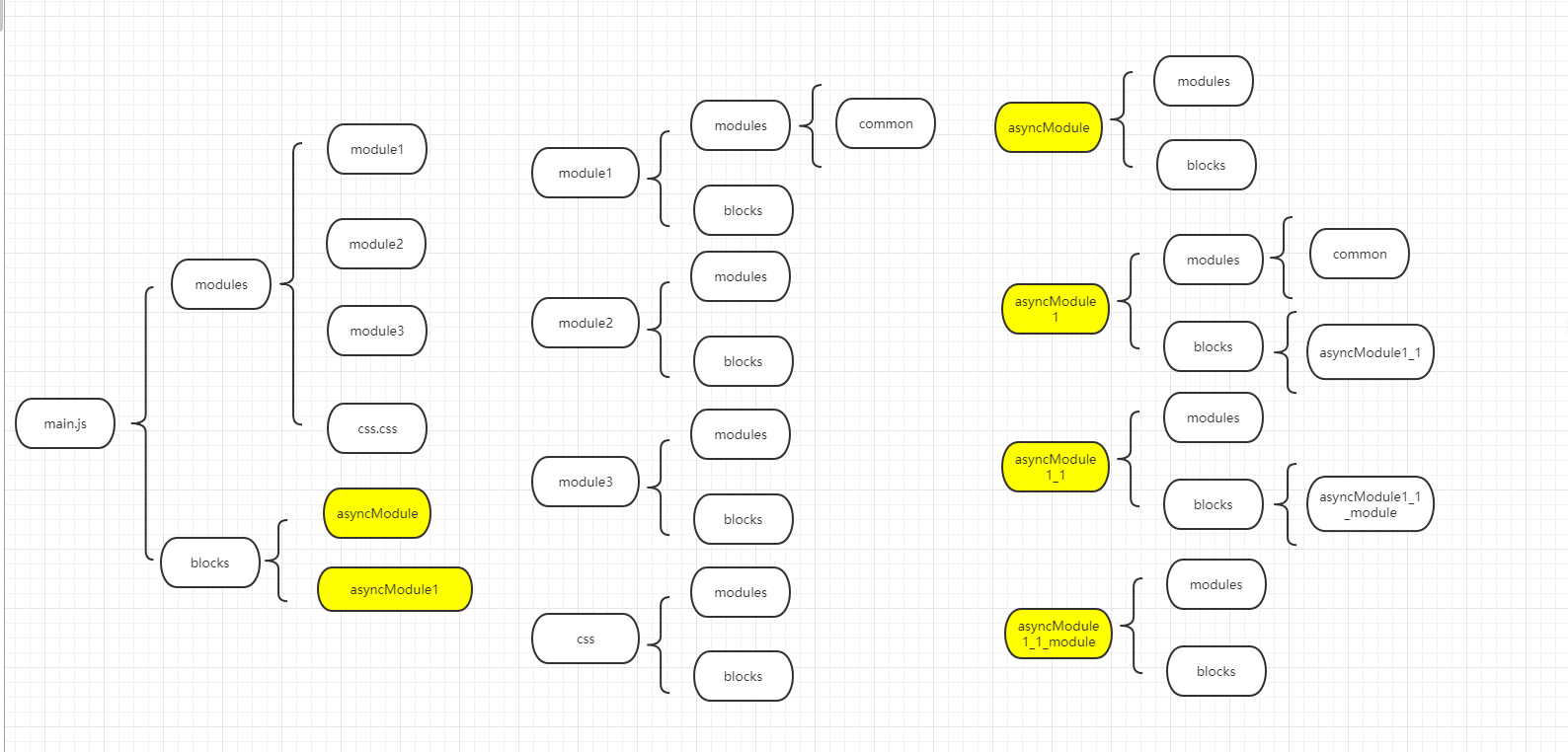
那么其作用总结如下:
将其子同步 module 都放到 module 的 modules中,异步 module 放在blocks中,并创建一个新的包含
{ modules : [],blocks:[]}对象在一个 module 中如果递归深入遍历,生成 module 树,只是找寻每一个 module 下一级依赖的 module.
但是我们很多时候会存在子模块中也会依赖其他的同步子模块,就想上面的对于异步加载模块其会生成一个新的 chunk 文件,但是同步子模块的同步子模块也应该加载到此 chunk 中,就如上面的 main.js 其不直接依赖于 common.js 但是其同步子模块 module1.js 依赖于 common.js,所以对于 main.js 其也应该加载 common.js 文件。这就是下面处理的
第二步: inputChunkGroups.reduce(reduceChunkGroupToQueueItem, []).reverse()和 while (queue.length){}
js
const visitModules = (
compilation,
inputChunkGroups,
chunkGroupInfoMap,
chunkDependencies,
blocksWithNestedBlocks,
allCreatedChunkGroups
) => {
const logger = compilation.getLogger("webpack.buildChunkGraph.visitModules");
const { namedChunkGroups } = compilation;
// 省略...
/** @type {Map<ChunkGroup, { index: number, index2: number }>} */
const chunkGroupCounters = new Map();
// 对于入口chunkGroup创建一个map保存两个下标值 index 和 index2
for (const chunkGroup of inputChunkGroups) {
chunkGroupCounters.set(chunkGroup, {
index: 0,
index2: 0,
});
}
let nextFreeModuleIndex = 0;
let nextFreeModuleIndex2 = 0;
/** @type {Map<DependenciesBlock, ChunkGroup>} */
const blockChunkGroups = new Map();
const ADD_AND_ENTER_MODULE = 0;
const ENTER_MODULE = 1;
const PROCESS_BLOCK = 2;
const LEAVE_MODULE = 3;
/**
* @param {QueueItem[]} queue the queue array (will be mutated)
* @param {ChunkGroup} chunkGroup chunk group
* @returns {QueueItem[]} the queue array again
*/
const reduceChunkGroupToQueueItem = (queue, chunkGroup) => {
// 对于入口chunks 获取其 entryModule 然后变成 action为 ENTER_MODULE的queue信息 (入口module)
for (const chunk of chunkGroup.chunks) {
const module = chunk.entryModule;
queue.push({
action: ENTER_MODULE,
block: module,
module,
chunk,
chunkGroup,
});
}
chunkGroupInfoMap.set(chunkGroup, {
chunkGroup,
minAvailableModules: new Set(),
minAvailableModulesOwned: true,
availableModulesToBeMerged: [],
skippedItems: [],
resultingAvailableModules: undefined,
children: undefined,
});
return queue;
};
// Start with the provided modules/chunks
/** @type {QueueItem[]} */
let queue = inputChunkGroups
.reduce(reduceChunkGroupToQueueItem, [])
.reverse();
/** @type {Map<ChunkGroup, Set<ChunkGroup>>} */
const queueConnect = new Map();
/** @type {Set<ChunkGroupInfo>} */
const outdatedChunkGroupInfo = new Set();
/** @type {QueueItem[]} */
let queueDelayed = [];
/** @type {Module} */
let module;
/** @type {Chunk} */
let chunk;
/** @type {ChunkGroup} */
let chunkGroup;
/** @type {DependenciesBlock} */
let block;
/** @type {Set<Module>} */
let minAvailableModules;
/** @type {QueueItem[]} */
let skippedItems;
// 创建异步的 block
const iteratorBlock = (b) => {};
/*
通过队列的方式去处理chunk的依赖
*/
while (queue.length) {
logger.time("visiting");
// 遍历处理当前
while (queue.length) {}
logger.timeEnd("visiting");
//
while (queueConnect.size > 0) {}
}
};上面的过程作用是: 通过两次循环的方式,将栈里面的同步 module 和其一层层依赖的同步 module 添加的 chunks._modules 中。
在一开始将入口 module、chunk、chunkGroup 作为参数,添加到 quequ 中,然后这时候 queue 中只有一个入口 module 的数据,
然后通过 ENTER_MODULE -> PROCESS_BLOCK(一方面将当前依赖的 同步 module 添加到 queue 队列中,一方面将异步 module 通过 iteratorBlock()创建其对应的 chunk、chunkGroup 和添加到 queueConnect 队列中),然后在while (queue.length) {}中存在当前 block 依赖的同步 module 队列数据,然后对于同步 module 经历 ADD_AND_ENTER_MODULE(建立当前 chunk 与 module 之间的关系) -> ENTER_MODULE(建立 module 在 chunkGroup 中的下标和 module 本身的 index 下标 ) -> PROCESS_BLOCK(处理子 module 中依赖的同步 module 和异步 module)
在上一次 ENTER_MODULE 中其又在 quequ 添加了一个 action 为 LEAVE_MODULE 的对象,那么这个 module 又会在以后进行一次 LEAVE_MODULE(建立 module 在 chunkGroup 中_moduleIndices2 的下标和 module 本身的 index2 下标)
从上面我们可以简单总结一下对于一个入口 module,在第一步: visitModules建立了一个 blockInfoMap 对象存了每一个 module 其下一级依赖的 modules 和 blocks,然后再while (queue.length){ while (queue.length) {} }的方式从入口 module 开始,
作为一个入口 module,肯定存在对应的 chunk、chunkGroup,然后通过 ENTER_MODULE -> PROCESS_BLOCK 遍历出
blockInfoMap[入口module]同步 module 添加到 queue 作为ADD_AND_ENTER_MODULE在后面处理,异步 block 创建每一个异步 module 对应的 chunk、chunkGroup 然后放到 queueConnect 在下一个 while 中处理继续处理 queue,
queue === [ 同步module1, 同步module2 ...,入口module的LEAVE_MODULE任务]拿出入口 module 依赖的 module1, 这时候其作为一个ADD_AND_ENTER_MODULE,会经历 ADD_AND_ENTER_MODULE -> ENTER_MODULE-> PROCESS_BLOCK 的过程,分别建立 module 与当前 chunk 之间的关系,module 在 chunk 中_moduleIndices2的下标和本身的 index 下标,处理 module 中依赖的下一级 modules 和 blocks,还有对每一个 module 还会再次最为一个任务(action:LEAVE_MODULE)添加到 quequ 中。
所以在第二步其 queue 中可能会变成这个样子 queue === [ 同步module2 ..., 入口module的LEAVE_MODULE任务 , 同步module1的下一级同步module1-1,同步module1的下一级同步module1-2 ... , 同步module1的LEAVE_MODULE任务 ],这样不断的循环就建立了一个 chunk._modules 保存了其整个树下依赖的所有的同步 module,也分割出一个个异步 block 的 chunk,同时通过 chunkDependencies、queueConnect 保存 chunkGroup 之间的依赖关系。
上面处理的是第二层中的 queue 的循环,下面就是 queueConnect 的遍历。
再次我们需要了解一下这个对象 chunkGroupInfo,其存在一下属性
- chunkGroup
当前 chunkGroupInfo 的 chunkGroup 对象
- minAvailableModules: new Set(),
chunkGroup 可追踪的最小 module 数据集
minAvailableModulesOwned: true,
availableModulesToBeMerged: []
遍历环节所使用的 module 集合
skippedItems: [],
resultingAvailableModules: undefined,
children: undefined
在对 queueSize 的遍历过程中其主要作用是遍历当前 chunkGroup 下依赖的第一层异步 block,然后创建每一个异步 block 的 blockInfo 对象并且 push 到 queue 数组中,那么就又会进行双层遍历(遍历此异步 block 下的同步 module 和第一层异步 module),并且将父chunk._modules(chunk.modulesIterable)作为当前 chunkGroupInfo 的minAvailableModules。
这样通过双层循环遍历的方式 就将一个入口 module 中拆分成以入口、异步调用的 chunkGroup 为集合的 chunk 和 chunk 下的同步 modules
connectChunkGroups
chunk-entry-chunk-chunkGroup-chunkGroup-2.png